
In order to come up with greater insights and compare notes, each person on our team spent time training their own rendition of various deep reinforcement learning agents. A summary of all the agents, their architecture, limitations, and their training regimen can be found here. Stats for each agent can be found at the leaderboard
Baseline Agents
These are the agents we primarily used for training and benchmarking.
Random
This agent responds with a random action every timestep. It usually ends up bombing itself in the first 40 timesteps of the game.
Static
This agent does absolutely nothing, simply sitting where it spawned. It’s useful for training aggresiveness in agents that might otherwise learn not to place bombs.
SimpleAgent
This is a rule-based deterministic agent that was created by the Pommerman developers. It generally does quite well, however it can be tricked and does have a few weaknesses that can be exploited.
SmartRandom
This agent is the same as the random agent, except it uses the action filter developed for the Skynet agents. Details on that action filter can be found in this paper.
Also of note, this agent was entered into the NeurIPS 2018 competition and achieved 7th place overall!
Skynet
The Skynet agents are a set of agents based on the AI architecture developed by the Borealis AI group. The architecture uses the PPO (Proximal Policy Optimization) algorithm with GAE (Generalized Advantage Estimation) with this neural network architecture:
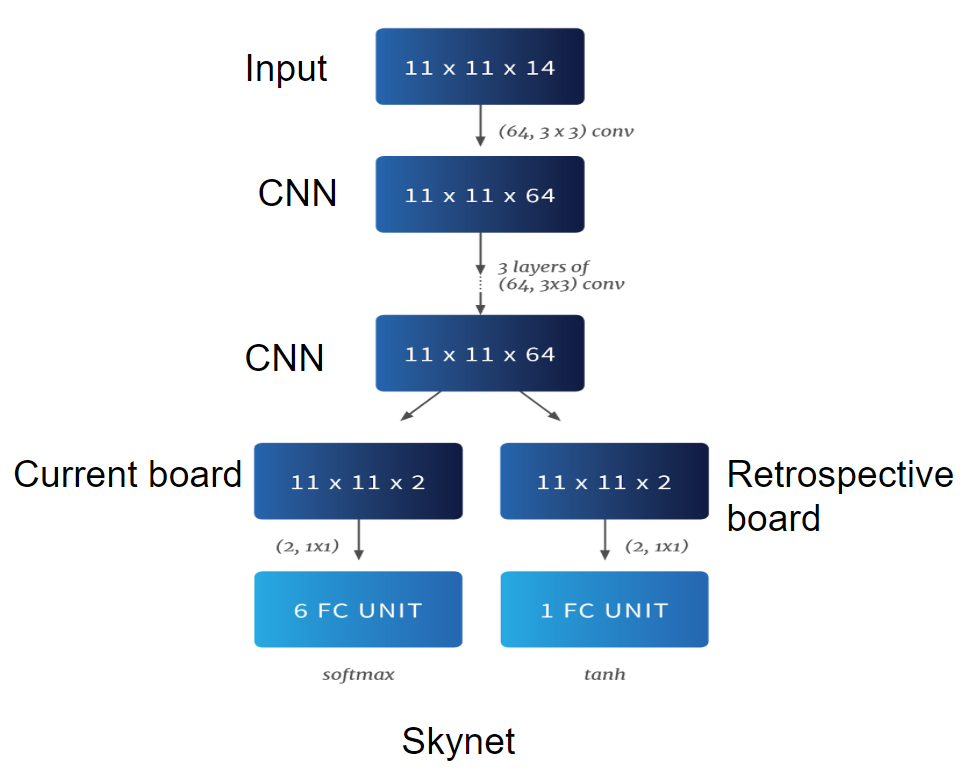 Note that retrospective board essentially gives the neural network a look at one timestep in the past with the hope that it will be able to predict the future better.
Note that retrospective board essentially gives the neural network a look at one timestep in the past with the hope that it will be able to predict the future better.
In addition to the aforementioned architecture, all Skynet agents are fed a pre-filtered set of actions that generally keeps them from making any moves that would definitely kill them. This action filter is the primary basis for Skynet’s performance, and is likely the only reason the Skynet agents really do well. SmartRandom agents (which use this same action filter) achieve similar performance as the trained agents, which means Skynet agents are really only doing a little better than random most of the time.
Skynet955
This was the original agent entered into the NeurIPS 2018 Pommerman competition. It achieved 5th place overall and was 2nd place in the learning agent category (deterministic tree pruning algorithms took the top 3 spots in the competition).
The 955 in its name is derived from the fact that it was trained for 955 iterations (most likely over 90,000 games and 72M timesteps).
Skynet100
This is an agent we trained on an empty field against static agents. It achieved good performance against them, but overfit to their positions, resulting in a trivial strategy that broke once the enemy agent position was changed. It was trained on 5,000 games.
Skynet100_mod
This was a retrained agent update that started learning against randomized enemy agent positions, which made it much more robust than its sibling. It was trained on 5,000 games.
Skynet6407
This agent took into account everything we had learned from previously trained agents and attempted to get over a wall of sparse reward. It was trained on a curriculum of static agents with randomized starting positions with a field that gradually increased in obstacle density. Unfortunately, even after 6407 iterations (~320,000 games or >100M timesteps) it was not able to learn how to “tunnel” through boxes in order to reach an enemy agent which could not be reached any other way. Curriculum improvements and further reward engineering may have been able to remedy this, but we ran out of time to experiment.
Looking at our leaderboard, this agent seems to achieve slightly better performance than Skynet955, which hopefully is an indicator of the effectiveness of our curriculum.
Pommerman-baseline agents
These agents were taken from pommerman-baselines.
Imitation256
The data collected on the Simple agent was used to train this agent to imitate that behaviour. It was then trained on 5000 games.
MCTS256
This agent uses Monte Carlo tree search with neural network guidance. It was then trained on 5000 games.
MCTS
This agent does pure Monte Carlo tree search.
300M Timestep Agent
This agent was trained on a 4x4 board against a variety of increasingly difficult opponents:
- static agent
- static agent spawning at random locations
- random agent that never uses bombs
- random agent that uses bombs
Following this training regimen, the agent was transferred to a 6x6 board, where it completed another 50M training steps against the random (no bomb) agent.
Bugfinder
This agent was trained on a 8x8 empty board against SimpleAgent with 5 million iterations, using generic PPO algorithm provided by stable-baseline. The policy network is also a generic one with 2 fully connected layers. It interestingly and surprisingly learned a bug inside implementation of SimpleAgent, and exploited it to win. See our blog post for detail.
CNN Agent
This agent was also trained with PPO algorithm provided by stable-baseline, but with a custom CNN policy network. See our blog post for detailed CNN architecture explanation.
It was trained against the static agent on boards with an increasing number of boxes. When the starting locations were randomized, however, it never learned how to reliably find the other agent. We now theorize that this was due to insufficient depth in the model (2 convolutional layers and 2 dense layers), but regardless, the requirements were relaxed to fixed positions. The agent then learned to reliably path find its way to the other agent, though it would get stuck if there wasn’t a path, as it only learned to place bombs next to the other agent. This is likely due to overfitting, because it never had to bomb its way through obstacles, so it never learned how. The next step would be to integrate this curriculum with that of the variable board sizes, so it could learn how to navigate through boxes with a much smaller random walk to the initial reward.